
 |
| map for science? |
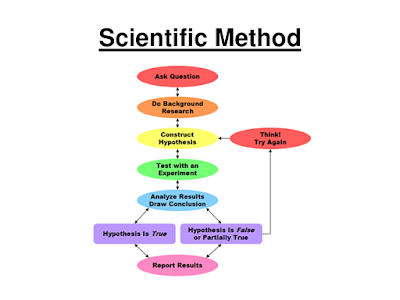
You were probably told sometime early on about the map for science: the scientific method. It was probably displayed for your high school class as a tidy flowchart showing how a hypothetico-deductive approach allows scientists to solve problems. Scientists make observations about the natural world, gather data, and come up with a possible explanation or hypothesis. They then deduce the predictions that follow, and design experiments to test those predictions. If you falsify the predictions you then circle back and refine, alter, or eventually reject the hypothesis. Scientific progress arises from this process. Sure, you might adjust your hypothesis a few times, but progress is direct and straightforward. Scientists aren’t shown getting lost.
Then, once you actively do research, you realize that formulation-reformulation process dominates. But because for most applications the formulation-reformulation process is slow – that is, each component takes time (e.g. weeks or months to redo experiments and analyses and work through reviews) – you only go through that loop a few times. So you usually still feel like you are making progress and moving forward.
But if you want to remind yourself just how twisting and meandering science actually is, spend some time fitting dynamic models. Thanks to Ben Bolker’s indispensible book, this also comes with a map, which shows how closely the process of model fitting mirrors the scientific method. The modeller has some question they wish to address, and experimental or observational data they hope to use to answer it. By fitting or selecting the best model for they data, they can obtain estimates for different parameters and so hopefully test predictions from they hypothesis. Or so one naively imagines.
 |
| From Bolker's Ecological Models and Data in R, a map for model selection. |
“Consider the number of different models that can be constructed from the simple Lotka-Volterra formulation of interactions between two species, layering on realistic complexities one by one. First, there are at least three qualitatively distinct kinds of interaction (competition, predation, mutualism). For each of these we can have either an implicit accounting of basal resources (as in the Lotka-Volterra model) or we can add an explicit accounting in one particular way. That gives six different models so far. We can then add spatial heterogeneity or not (x2), temporal heterogeneity or not (x2), stochasticity or not (x2), immigration or not (x2), at least three kinds of functional relationship between species (e.g., predator functional responses, x3), age/size structure or not (x2), a third species or not (x2), and three ways the new species interacts with one of the existing species (x3 for the models with a third species). Having barely scratched the surface of potentially important factors, we have 2304 different models. Many of them would likely yield the same predictions, but after consolidation I suspect there still might be hundreds that differ in ecologically important ways.”Model fitting/selection, can actually be (speaking for myself, at least) repetitive and frustrating and filled with wrong turns and dead ends. And because you can make so many loops between formulation and reformulation, and the time penalty is relatively low, you experience just how many possible paths forward there to be explored. It’s easy to get lost and forget which models you’ve already looked at, and keeping detailed notes/logs/version control is fundamental. And since time and money aren’t (as) limiting, it is hard to know/decide when to stop - no model is perfect. When it’s possible to so fully explore the path from question to data, you get to suffer through realizing just how complicated and uncertain that path actually is.
 |
| What model fitting feels like? |
Bolker hints at this (but without the angst):
“modeling is an iterative process. You may have answered your questions with a single pass through steps 1–5, but it is far more likely that estimating parameters and confidence limits will force you to redefine your models (changing their form or complexity or the ecological covariates they take into account) or even to redefine your original ecological questions.”
I bet there are other processes that have similar aspects of endless, frustrating ability to consider every possible connection between question and data (building a phylogenetic tree, designing a simulation?). And I think that is what science is like on a large temporal and spatial scale too. For any question or hypothesis, there are multiple labs contributing bits and pieces and manipulating slightly different combinations of variables, and pushing and pulling the direction of science back and forth, trying to find a path forward.
(As you may have guessed, I spent far too much time this summer fitting models…)
(As you may have guessed, I spent far too much time this summer fitting models…)






